Who AM I?
I am an experience data scientist and passionate about deep learning, big/geospatial data mining and implementing the techniques to explore the world and solve complex problems.
The methods I implemented in my daily work usually cover:
* Supervised learning - regression, classification, recommendation system and time-series forecast
* Unsupervised learning - anomaly detection, clustering and synthetic data generation etc.
My Data Science Career
2021-present, Data scientist, tech lead @AppDynamics, part of Cisco. The core business of AppDynamics is full-stack observability. In the data science team, we implement MELT (metric, event, log and trace) data to provide various ML features, including log-analytics, outlier detection, to the observability products.
2018-2021, Senior data sciensist @Threatmetrix, part of LexisNexis Risk solution.
In the TMX machine learning team, our main business goal is to deliver best digital experience and solutions to our customers.
I mainly worked on two projects:
1. Using customer transaction data to train supervised learning models. We implemented Bayesian optimization to perform hyperparameter fine-tuning to deliver the optimal ML solution.
2. Designed a prototype ML performance monitoring platform. The goal is to identify unhealthy running machines or nodes in the data center such that DevOps can proactively respond the issues.
2017-2018, Data scientist @Picarro, an environmental and utility service company. @Picarro, we integrate data analytics with an advanced vehicle-based methane emissions data collection platform for optimal leak detection solutions.
2016-2016, Data scientist/machine learning engineer consultant @ZX Venture, Anheuser-Busch InBev. There I explored the possibility of impelmenting recommendation and the e-commerence data for the beer company. I developed a prototype beer recommendation engine, Beer Recommender, using content-based/collaborative filtering.
2016-2016, Data engineering fellow at Insight Data Science. @Insight, I devised a data pipeline platform, TipMax, to visualize GIS NYC taxi tips data.
Prior to data scientist, my academic background is computational physics. My research focus was on numerical simulations on exotic quantum materials. For more detail, please see my research background. Many of the numerical algorithms I have been working on are actually related to and have the same math languages to machine learning. Therefore, to me, doing research on machine learning is like physics research.
Fraud Detections in FinTech
Gas Leak Risk Analysis and Geospatial Data Mining
At Picarro, I mainly focused on predicting natural gas leaking behavior and provided risk-based analysis. Using data analytics by integrating the DIMP model and Picarro Methane data, and determine the optimal survey solution to find as many risky leaking as possible (as shown below).
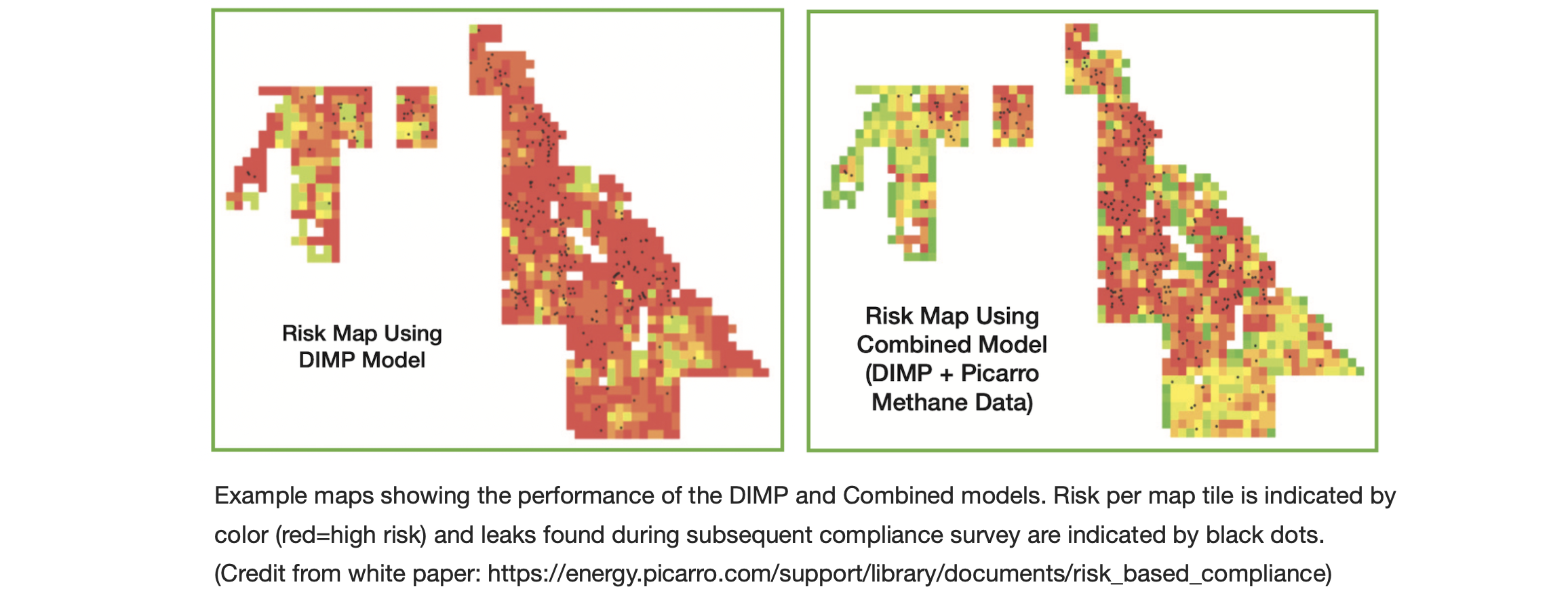
The risk-based survey model is determine by a variety of data mining methods. In addition to traditional regression models, I also impelmented Bayesian inference and geospatial data mining, i.e. the spatial regression model considering neighboring effect and spatial correlation in the risk-based survey model.
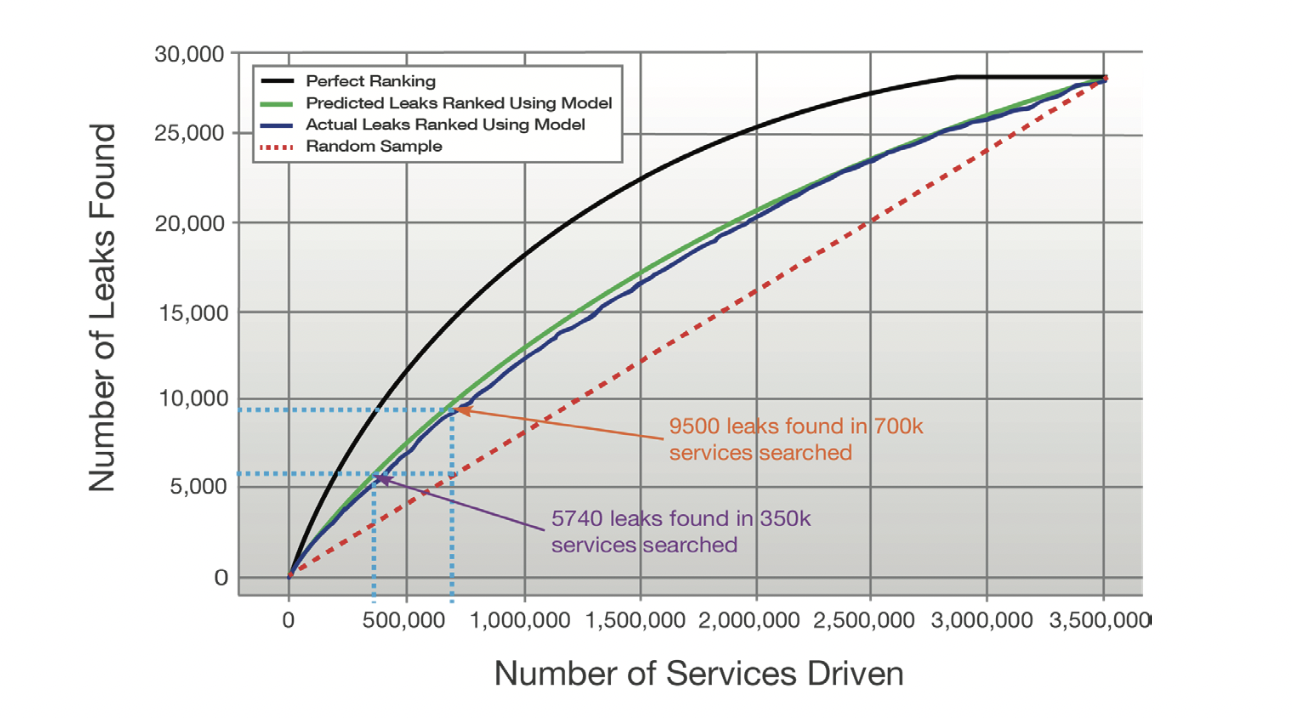
Above result shows number of Leaks found vs. number services surveyed using the model (credit from Picarro Risk Based Compliance). Without a risk-based survey model, the number of leaks found increases linearly (red) with the number of services. Applying a risk-based model improves this performance. A perfectly performing model (black) is shown compared to a prediction of model performance (green) and actual model performance (blue). We can see the model is helpful to capture more leaks with the same effort on survey services.
Beer Recommender
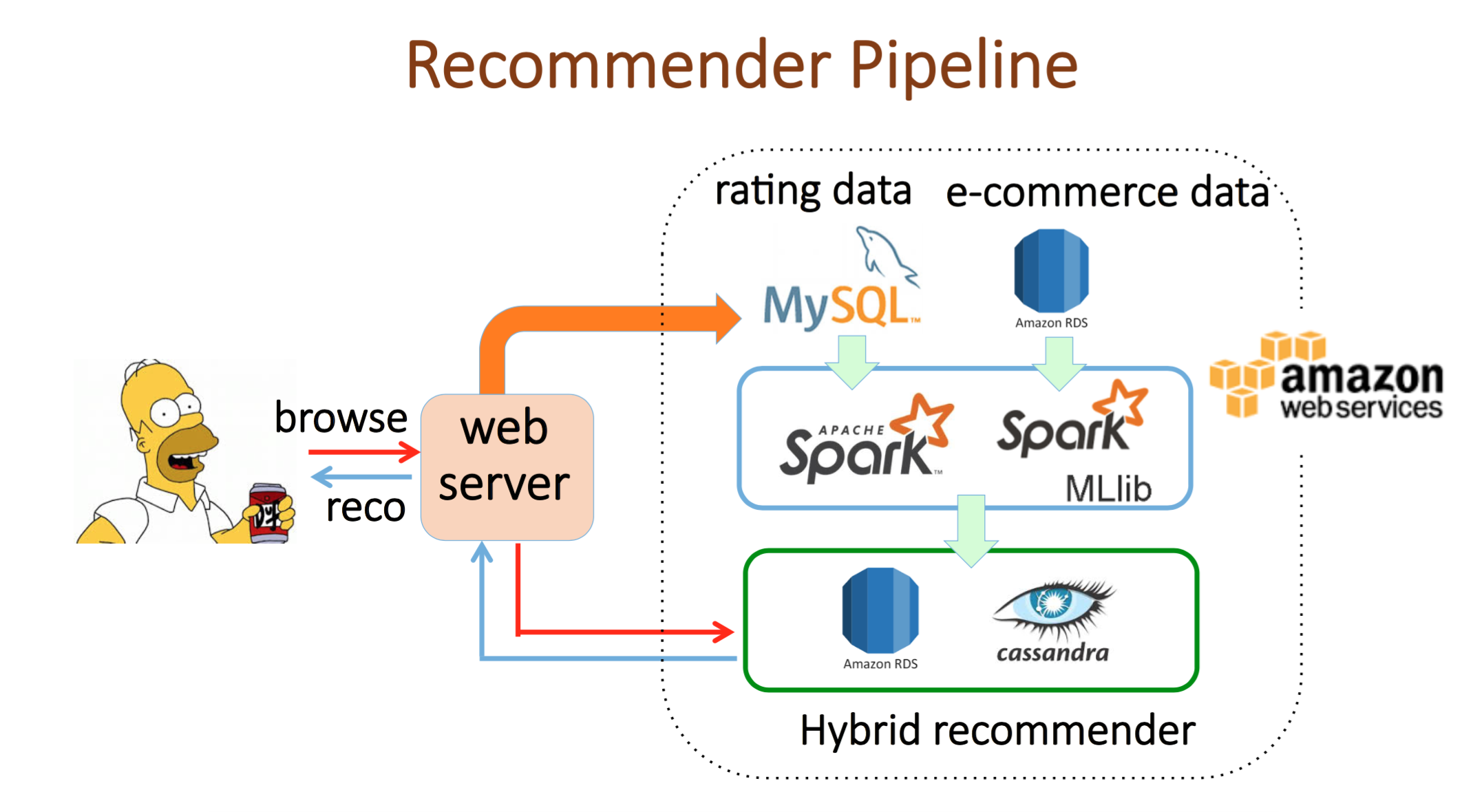
In this project, I integrated beer attributes, customers' ratings and purchase history to design a recommendation engine. The system provides item-item and user-item recommendation hybrizing the content-based and collaborative filtering. The prototype engine gives user-item recommendation and item-item recommendation. Such as recommender is personalized since each customer has different preferences and tastes. The pipeline of the prototype recommendation engine is shown below. In the backend, the recommendation tables are prepared offline using Spark and loaded into AWS databases. For more details, please see the presentation slides
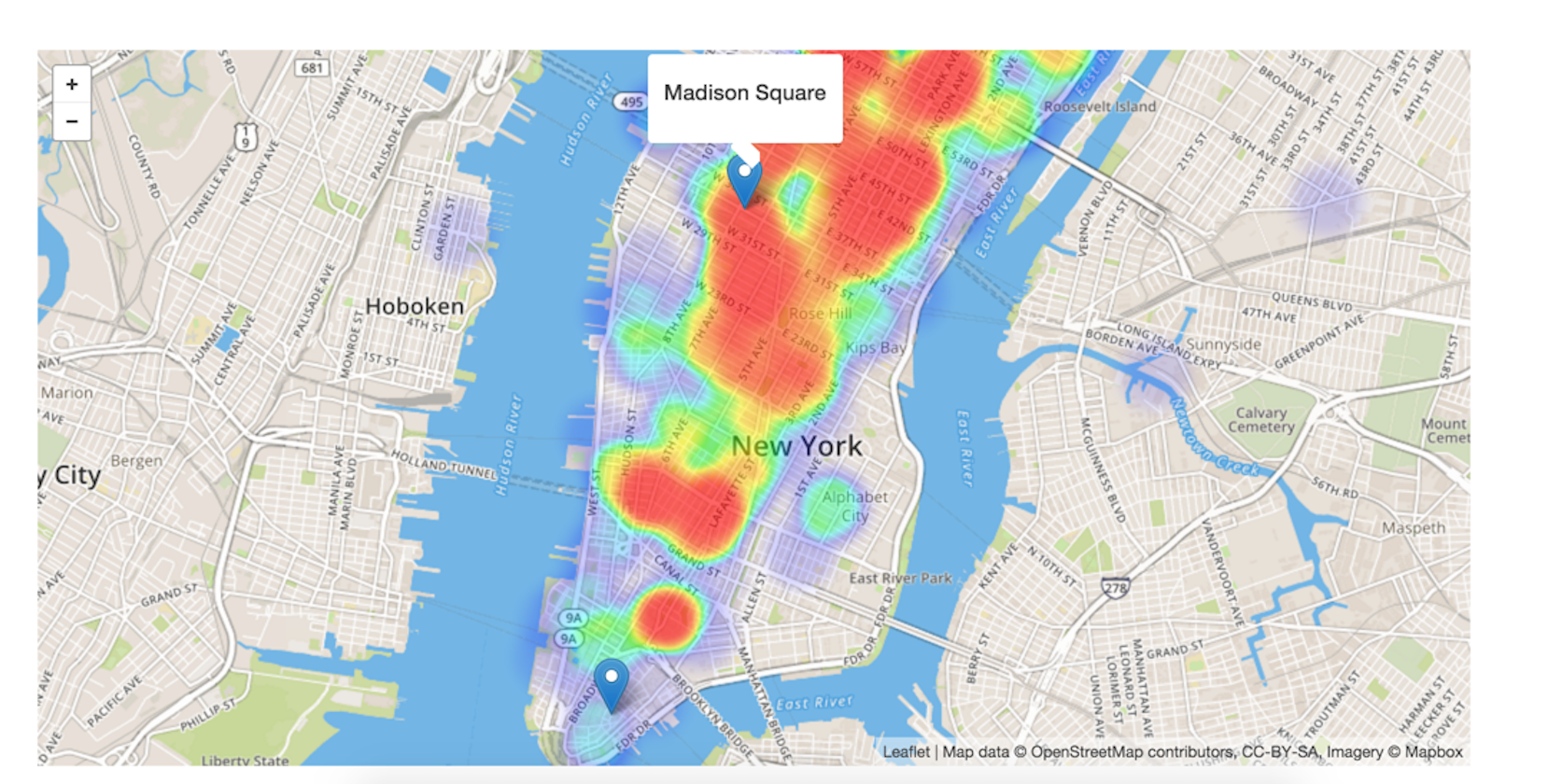
TipMax
My Insight project is to design a big-data web app, named TipMax, to help the New York city taxi drivers to maximize their incomes. The app uses MapBox to visualize the pick-up locations, the GIS profiles of the tip percentage ( defined by tips/fare) and the total fare that passengers paid, using the New York city data during 2009 Jan. -2015 June (totally about 220 GB).
In the project, I designed a data pipeline using Spark for data cleaning and NoSQL database Cassandra for GIS data storage. I also developed the real-time streaming platform using Kafka for data ingestion and Spark streaming for data analysis to simulate real-time data flowing process, guiding the drivers what time and what places they can pick up passengers to earn higher tips/fare every 10 seconds. Meanwhile, I used the ARIMA model to forecast the best time and locations for higher tips.